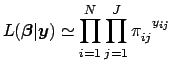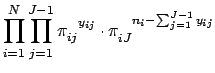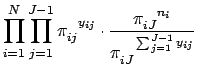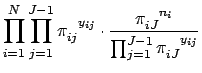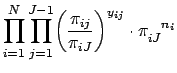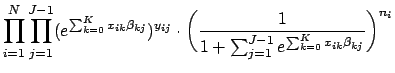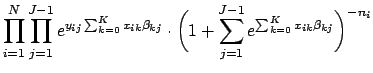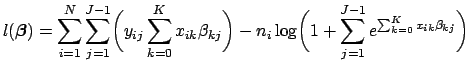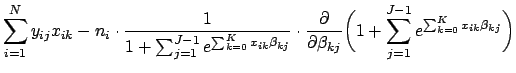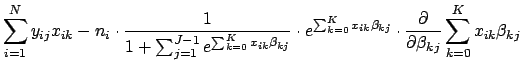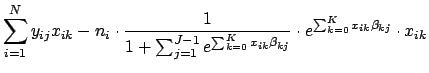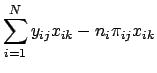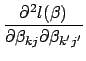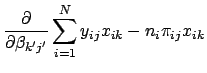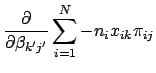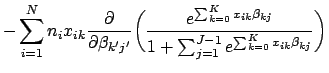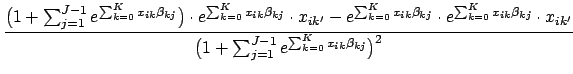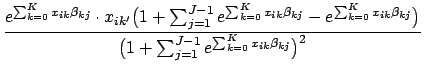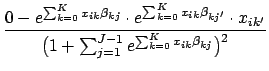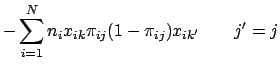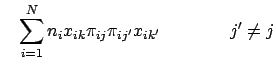When ![]() , this reduces to Eq. 2. The likelihood function is algebraically equivalent to Eq. 26, the only difference being that the likelihood function expresses the unknown values of
, this reduces to Eq. 2. The likelihood function is algebraically equivalent to Eq. 26, the only difference being that the likelihood function expresses the unknown values of
![]() in terms of known fixed constant values for
in terms of known fixed constant values for
![]() . Since we want to maximize Eq. 26 with respect to
. Since we want to maximize Eq. 26 with respect to
![]() , the factorial terms that do not contain any of the
, the factorial terms that do not contain any of the ![]() terms can be treated as constants. Thus, the kernel of the log likelihood function for multinomial logistic regression models is:
terms can be treated as constants. Thus, the kernel of the log likelihood function for multinomial logistic regression models is:
Taking the natural log of Eq. 30 gives us the log likelihood function for the multinomial logistic regression model:
As with the binomial model, we want to find the values for
![]() which maximize Eq. 31. We will do this using the Newton-Raphson method, which involves calculating the first and second derivatives of the log likelihood function. We can take the first derivatives using the steps similar to those in Eq. 11:
which maximize Eq. 31. We will do this using the Newton-Raphson method, which involves calculating the first and second derivatives of the log likelihood function. We can take the first derivatives using the steps similar to those in Eq. 11:
Note that there are
![]() equations in Eq. 32 which we want to set equal to zero and solve for each
equations in Eq. 32 which we want to set equal to zero and solve for each
![]() . Although technically a matrix, we may consider
. Although technically a matrix, we may consider
![]() to be a column vector, by appending each of the additional columns below the first. In this way, we can form the matrix of second partial derivatives as a square matrix of order
to be a column vector, by appending each of the additional columns below the first. In this way, we can form the matrix of second partial derivatives as a square matrix of order
![]() . For each
. For each
![]() , we need to differentiate Eq. 32 with respect to every other
, we need to differentiate Eq. 32 with respect to every other
![]() . We can express the general form of this matrix as:
. We can express the general form of this matrix as:
We can now express the matrix of second partial derivatives for the multinomial logistic regression model as:
![$\displaystyle f(\boldsymbol{y}\vert\boldsymbol{\beta}) = \prod_{i=1}^N \biggl[\...
...\prod_{j=1}^J y_{ij}!} \cdot \prod_{j=1}^J \pi_{ij}^{\phantom{ij}y_{ij}}\biggr]$](img111.png)